Bilder verändern (Komprimieren, Maße, Dateiname): was passiert beim Bildersuche-Ranking?

Immer wieder taucht die Frage auf: Was passiert, wenn man gut rankende Bilder verändert. Also zum Beispiel: die Bilder leicht beschneiden, die Dateigröße komprimieren, die URL verändern (weil in einem anderen Ordner) oder den Dateinamen ändern. Häufig werden solche Fragen im Zusammenhang mit einem Relaunch oder Server-Umzug gestellt. Verliert das Bild dann seine Position in der Google Bildersuche? Wird das Bild sofort de-indexiert? Da meine bisherigen Artikel zu dem Thema veraltet sind, hier noch mal die Best-Practise-Tipps.
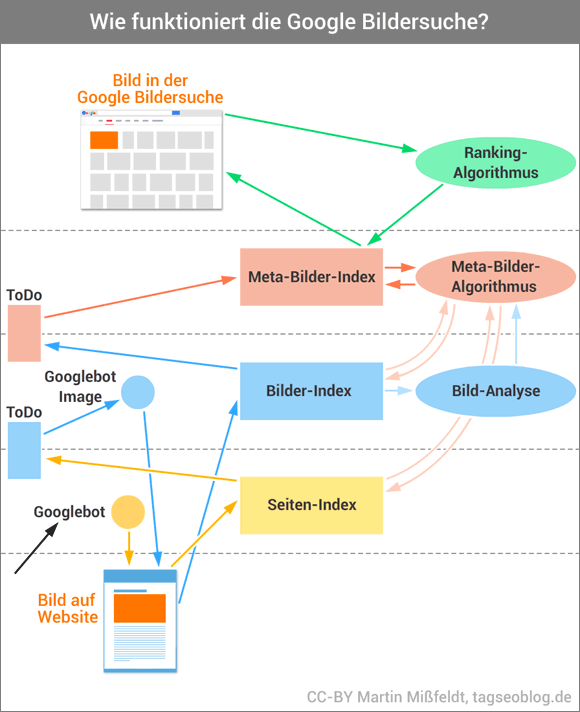
Die Fragen beantworten sich weitgehend von selber, wenn man das Prinzip der Verarbeitung von Bildern im Google-Index versteht. Da Google hierzu keine Auskunft gibt, habe ich ein Modell entwickelt, was die Vorgänge plausibel beschreibt.
Das Meta-Bild
Wenn ich ein neues Bild bei Google hochlade, dann speichert Google nicht „mein“ Bild – sondern „das“ Bild. Google erzeugt quasi eine interne Kopie dieses Bildes und legt es in seinen Index. In meinem Bilder-SEO-E-Book habe ich es „das Meta-Bild“ genannt. Der Inhalt dieses Meta-Bildes wird zunächst mit Hilfe komplizierter Algorithmen („künstliche Intelligenz“) geprüft. Dabei versucht Google maschinell zu erkennen, was auf einem Bild zu sehen ist. Diese Algorithmen werden immer besser darin, Bilder tatsächlich richtig zu verstehen. Man kann das eindrucksvoll mit der Cloud-Vision-Api von Google testen. Dieser Vorgang dauert – dazu unten mehr …
Wenn das Bild dann schließlich als Meta-Bild im Google-Index gelandet ist, wird eine Referenz zu dem Fundort hergestellt. Die Onpage-Signale werden ausgewertet und die wichtigen Keywords dem Bild zugeordnet. Solange es dieses Bild nur einmal gibt, wird immer die Quell-Seite in der Bildersuche verlinkt.
Nun kann es aber sein, dass das gleiche Bild – in veränderter Form – noch einmal im Web auftaucht. Aus dem Grund vergleicht Google jedes neu zu indexierende Bild mit allen anderen, die bereits im Index sind. Das geschieht mit Hilfe eines Vereinfachungsalgorithmus (wie genau, würde hier zu viel Raum einnehmen).
Wenn das Bild ungefähr so aussieht wie ein bereits indexiertes Meta-Bild, dann wird es diesem hinzugerechnet. Bzw. genau genommen wird die neue Bild-URL beim Meta-Bild ergänzt. Hier eine Veranschaulichung einer solchen Meta-Bild-Karteikarte:

Zwei Bilder, die sich sehr ähnlich sind, sind also nur ein Meta-Bild im Google-Index. Das Meta-Bild hat dann zwei Referenz-URLs zu Websites, auf denen das Bild gezeigt wird.
Jedes Meta-Bild taucht nur einmal in einer Google-Bildersuche auf. Dadurch will Google vermeiden, dass zu viele ähnliche Versionen von letztlich ein und demselben Bild in der Bildersuche zu finden sind. Ich habe den Vorgang mal in einer Infografik zusammengefasst. Ich hoffe, es wird deutlich, auch wenn die Details natürlich noch viel komplexer sind. Nicht ohne Grund hat mein E-Book fast 170 Seiten …
Vor diesem Hintergrund wird hoffentlich deutlich, wie man im Falle einer Bild-Veränderung vorgehen muss. Für das Folgende muss man beachten: wenn ich von „identischem Bild“ spreche, dann meint das, dass Dateigröße und Bildmaße identisch sind. So ein Bild ist also eine exakte (!) Kopie eines anderen Bildes.
Bild-Dateiname ändern
Kein Problem! Wenn Google das identische Bild findet, wird dieses Bild-Datei schnell (ohne langwierige Bilderkennungsanalysen und -vergleiche) dem entsprechendem Meta-Bild zugeordnet.
Bild-URL verändern
Wenn man das Bild einfach nur verschiebt und den Speicherort ändert: auch kein Problem. Hierbei gilt das, was unter Punkt 1. beschrieben wurde. Allerdings würde ich bei größeren Bildermengen eher zu dem raten, was im Folgenden beschrieben wird.
Bild komprimieren (Dateigröße optimieren)
Achtung! Wenn sich Bildmaße oder Dateigröße verändern, dann handelt es sich aus Googles Sicht um ein neues Bild. Dann passiert folgendes: Google findet nicht mehr die Referenz des ursprünglichen Meta-Bildes zu der Website (weil das alte Bild weg ist, da es durch eine komprimierte Version ersetzt wurde). Google wird also die Verbindung zwischen dem Meta-Bild und der Website löschen. Das Meta-Bild bleibt aber im Google-Index (!). Wenn es eine andere Website gibt, die dieses Meta-Bild benutzt, dann wird Google diese Website in der Bildersuche verlinken (Hotlink). Wenn das Meta-Bild keine Referenz mehr hat, dann wird das Bild nicht mehr in der Google Bildersuche angezeigt (es ist scheinbar deindexiert).
Das neue Bild – das für ein menschliches Auge identisch aussieht – muss nun erst einmal wieder durch den „Sicherheitscheck“ der oben genannten Bilderkennung. Das dauert pro Bild einige Tage. Anschließend muss es wieder aufwändig verglichen werden, was erneut einige Tage dauern kann. Erst dann wird Google bemerken, dass es sich um eine Version des bereits vorhandenen Meta-Bildes handelt. Genau dann wird die Website, auf der das komprimierte Bild eingebunden ist, wieder dem Meta-Bild hinzugefügt – und ab dann wird das Bild wieder in der Bildersuche zu finden sein (wenn es bislang scheinbar weg war). Das Bild nimmt dann meist recht schnell wieder die alte Ranking-Position ein.
Was wichtig ist: dieser Prozess dauert mehrere Tage.
Bild beschneiden
Auch wenn man ein Bild nur an den Kanten etwas beschneidet, verändert das die Bilddatei in Größe und Maßen. Dann passiert das gleiche wie unter Punkt 3. beschrieben.
Ein Bild oder viele Bilder?
Die entscheidende Frage in diesem Zusammenhang ist die nach der Anzahl der Bilder. Wenn es nur ein oder zwei Bilder sind: kein Problem. Einfach komprimieren und ein paar Tage warten. Das Bild wird sich wieder in den alten Rankings einfinden.
Problematisch wird es immer dann, wenn es um größere Bildermengen geht. Der Bilderbot ist die meiste Zeit (ca. 95% seiner Aktivitäten) damit beschäftigt, bereits bekannte Bild-URLs abzurufen, um zu prüfen, ob ein Bild noch da ist. Wenn ein Bild nach 3-4 Aufrufen nicht mehr abrufbar ist, dann kappt der Bot die Verbindung zwischen Meta-Bild und der bisherigen Website. Wenn bei einem Relaunch plötzlich hunderte oder tausende Bilder verändert werden, dann wirft der Bot nach und nach (innerhalb weniger Tage) erst einmal alle Bilder aus dem Index (genau genommen fehlen dann die Verknüpfungen zwischen den Meta-Bildern und der Domain). Nach ca. 1-2 Wochen sind dann alle Rankings futsch.
Der Bilderbot nimmt sich dagegen nur sehr wenig Zeit (ca. 5%), neue Bilder zu indexieren. Es wird nun also Wochen und Monate dauern, ehe wieder alle Bilder überhaupt erst einmal vom Bilderbot eingesammelt wurden, und dann durch die Bilderkennungsschleifen zu gehen, um schließlich wieder den ursprünglichen Meta-Bildern zugeordnet zu werden. Da die Ressourcen für die Bilderkennung pro Domain begrenzt sind, wird sich diese Neuindexierungen sehr lange hinziehen.
Kurzum: bei großen Bildermengen sollte man so nicht (!) vorgehen.
Die Alternative beim Relaunch
Stattdessen sollte man die alten Bilder alle schön da liegen lassen, wo sie sind (die Dateien unter den bisherigen URLs). Die komprimierten Bilder werden mit einer anderen Bild-URL abgespeichert (das kann z.B. ein leicht veränderter Dateiname sein oder ein anderer Speicherort).
Auf der Website bindet man dann allerdings nicht mehr die alte Bildversion ein, sondern die neue.
Warum? Was passiert? Der Googlebot findet weiterhin die alten Bilder und wird daher an der Verknüpfung zwischen Meta-Bild und Website nichts ändern. Aber er findet auch neue Bilder, die dann in den Indexierungsprozess geschickt werden. Am Ende werden alle neuen Bilder jeweils dem passenden Meta-Bild zugeschlagen.
Das Bild wird also seine Ranking-Position behalten, und auch das Linkziel kann ununterbrochen zu der einbindenden Website gehen.
301-Weiterleitung oder nicht?
Sehr wichtig ist hierbei auch die korrekte Weiterleitung – bzw. eben die korrekte Nicht-Weiterleitung. Denn man darf in dem Fall natürlich keine 301-Weiterleitung vom alten zum neuen Bild anlegen. Denn das würde für den Googlebot bedeuten, dass das alte Bild nicht mehr da ist. Folglich würde er – wie oben beschrieben – die Verbindung kappen. Nur, wenn es keine 301-Weiterleitung gibt, bleibt das Bild für den Googlebot sichtbar und alles ist gut :-)
Ein 301 bedeutet bei (bearbeiteten) Bildern eigentlich nur: altes Bild ist weg! … Ein neues Bild muss so oder so seinen Weg gehen. Eine 301-Weiterleitung ist nur dann sinnvoll, wenn das Bild identisch ist (Dateigröße und Maße). Das ist nur dann der Fall, wenn sich er Dateiname ändert oder der Speicherort (s.o.).
Bleibt abschließend noch die Frage: wie lange muss man die alten Bilder bereithalten? Das kann man leider zeitlich nicht benennen. Die Antwort lautet: so lange, bis alle neuen Bilder gefunden und verarbeitet wurden. Das dauert – je nach Crawling-Budget und Anzahl der Bilder – durchaus Monate bis Jahre. Als grobe Hausnummer würde ich 12 Monate empfehlen.
Testen – testen – testen
Auch wenn das her Beschriebene so schon vielfach getestet wurde und funktioniert hat, so ist und bleibt es doch letztlich ein Modell. Im Einzelfall könnte es anders verlaufen. Daher ist der sicherste Weg immer, das Ganze frühzeitig (einige Wochen vorher) durch geeignete Tests zu verifizieren (z.B. indem man manuell einen Teil der Bilder komprimiert, auslagert etc.)
17 Gedanken zu „Bilder verändern (Komprimieren, Maße, Dateiname): was passiert beim Bildersuche-Ranking?“
Hey Martin,
ich danke dir für diesen klasse Artikel! Er beschreibt genau die Problematik, vor der wir bei einem Redesign stehen.
BG
Kai
Hallo Martin,
vielen Dank für den Artikel. Finde diesen wirklich sehr schlüssig und macht das Thema auch für einen Laien sehr anschaulich.
Inhaltlich habe ich allerdings ein paar Fragen bzw teile nicht ganz deine Einschätzung.
Bei den Punkten „Bild Dateiname ändern“ und „Bild-URL verändern“ sagst du, dass dies kein Problem darstellt. Hier gebe ich dir insofern Recht und teile deine Meinung, weil das Bild bei identischen Binärdaten logischerweise auch eine identische Checksumme auswirft und google somit sehr einfach die Assoziation zu dem Meta-Bild feststellen kann. Meiner Meinung nach – möchte man seinen Platz in den Suchergebnissen behalten – darf man allerdings den Bildnamen nicht einfach ändern, wenn man dadurch das Quellbild entfernt aufgrund der später aufgeführten Risiken, dass in erster Linie für das Meta-Bild ein 404 erkannt wird, während das neue Bild vermutlich erst später entdeckt und verarbeitet wird. Teilst du hier meine Ansicht, oder besteht dieses Risiko eigentlich nicht?
Ansonsten würde mich rein aus Neugier interessieren woher die Information mit der Aktivitätsverteilung des Bilderbots stammt, so dass dieser zu 95% damit beschäftigt ist den eigenen Datenbestand zu pflegen bzw zu verifizieren und nur zu 5% damit beschäftigt ist neue Bilder in den Index aufzunehmen. Gibt es hierzu eine Quelle oder handelt es sich eine Annahme.
Einen Rückschluss darauf zu schließen dass tote Bilder schneller aus dem Index fliegen als dass neue Bilder aufgenommen werden halte ich an der Stelle zumindest auch für gewagt, da man es hier technisch gesehen nicht mit einer einzigen Instanz zu tun hat, die dann tatsächlich sequentiell damit beschäftigt ist Job 1 abzuarbeiten, der aufgrund der Datenmenge 95% der Zeit einnimmt um danach mit Job 2 zu beginnen, der wiederum nur 5% der Zeit in Anspruch nimmt. Das System ist durch die verteilten Systeme meiner Meinung nach deutlich komplexer und man müsste hier tatsächlich definieren was dieser Bilderbot denn eigentlich genau tut und woher er wiederum seine Daten bezieht, die abzuarbeiten sind.
Bevor das hier nun aber zu ausschweifend wird als kurze Frage: sind diese Zahlen irgendwie verifizierbar, sind es Annahmen oder sind diese einfach nur ein gewähltes Mittel um den Artikel nicht zu komplex werden zu lassen?
Viele Grüße
Andreas
Danke für die (kritischen) Nachfragen, Andreas.
zu 1.: Stimmt, ich hätte klarer hervorheben sollen, dass es im Falle eine Dateinamensänderung sinnvoll ist, eine 301-Weiterleitung zu setzen. Bei sehr großen Bildermengen ist zudem jede Änderung ein potentielles Risiko, daher besser so verfahren, wie weiter unten beschrieben.
Zu 2: ich mache seit Jahren stichprobenartige Auswertungen meiner Logfiles. Daher weiß ich, dass die meisten Aufrufe des Google-Bilderbot auf Dateien gehen, die schon lange im Index sind. Ich hatte das mal irgendwann statistisch ausgewertet (nur bezogen auf einen Zeitraum von 2 Wochen und ca. 20 Domains von mir), und da kam ein Wert von 95 – 5 heraus. Kann schon sein, das das eher 90 zu 10 oder so ist. Im Grunde ist der genaue Wert egal, entscheidend scheint mir zu sein, dass der Bilderbot eben sehr viel Zeit damit verbringt, alte Bilder zu prüfen – was auch logisch ist, finde ich.
ZU Punkt 3: in meinem E-Book habe ich mir dazu viele Gedanken gemacht. Ich denke, es gibt mehrere „ToDo-Listen“, die abgearbeitet werden (siehe auch Infografik oben im Artikel). Die Bots bzw. Algorithmen arbeiten Listen ab, auf denen Quellen bzw. Bilder verzeichnet werden.
Dass Bilder sehr schnell aus dem Index verschwinden, weiß vermutlich jeder, der schon mal versehntlich die Robots.txt falsch gesetzt hat. Es dauert natürlich immer eine gewisse Zeit (ca. 2-3 Tage), ehe der Bot nach mehrmaligen Aufrufversuchen bemerkt hat, dass eine Bilddatei weg ist. Aber ab dann fliegen die Bilder oft in relativ kurzer Zeit aus dem Index.
Naja, und das das Neu-Indexieren bzw. die Neu-Listung im Bildersuche-Ranking seine Zeit dauert, wissen vermutlich auch die meisten.
Wie die Google-Bilersuche tatsächlich funktioniert, ist ein großes Google-Geheimnis – letztlich genau so wie beim organischen Algorithmus. Das Ganze ist ein recht komplexes Modell, dass ich im Laufe der Jahre erdacht habe – und das aus meiner Sicht plausibel ist und in vielen Fällen Rankingverhalten erklären kann.
Hallo Martin,
vielen Dank für die Erläuterungen. Es ging mir ganz sicher nicht darum, das Gesagte grundsätzlich in Frage zu stellen, zumal mir die Schlussfolgerung hier wirklich sehr gut gefällt und ich auch rein intuitiv – ohne auf eigens ausgewertete Logfiles zurückzugreifen – die selbe Handlungsempfehlung gegeben hätte.
Bei dem Auslasungsverhältnis hingegen denke ich allerdings, dass es hier auf den beobachteten Rahmen, sowie die Umstände ankommt und dass man das, selbst mit eigens ausgewerteten Logfiles (was aber wiederum eine Grundlage ist, die mich zufriedenstellt, weil es sich hier um belegbare Beobachtungen handelt), nicht in einem so einfachen Modell und Verhältnis ausdrücken kann.
Ich kann jetzt relativ wenig dazu sagen, wie das Verhältnis zwischen bestehenden und neuen Bilddateien bei deinen Projekten ist, aber dass die Aktivität des Bots davon abhängt, was der Crawler, der den HTML-Code auswertet, als Ressourcen liefert, denn das ist meiner Meinung nach die relevante Masse an URLs, die ein Bildbot zu überprüfen hat, was wiederum in den Logfiles sicher auch den hohen Wert ausmachen, während Bilder mint fehlenden Referenzen dann vermutlich periodisch nach einer gewissen Toleranzzeit aufgeräumt und aus dem Index entfernt werden, was mal schneller und mal langsamer gehen kann.
Ich würde nach der beschriebenen Beobachtung eher zu dem Schluss kommen, dass Google die Integrität der Bestandsdaten höher priorisiert als die Neuaufnahme in den Index, da das Primärziel einer Suchmaschine ist gültige und gute Ergebnisse zu liefern und im Zweifel nicht ganz so aktuell zu sein, als dass man den Nutzer damit verprellt ihn mehrfach auf Seiten oder Ressourcen zu schicken, die so nicht mehr existieren.
Ich würde hier lediglich zu dem Schluss kommen, dass es deutlich weniger Zeit beansprucht um aus dem Index zu fliegen oder bestehende indizierten Einträge zu aktualisieren, als in den Index aufgenommen zu werden, da – wie auch hervorragend beschrieben – dieser Prozess eben weitere Arbeitsschritte nach sich zieht, die dann ggf von anderen Engines erledigt werden müssen.
Meine Anmerkungen habe ich aber nur in bester Absicht geschrieben und ich freue mich wirklich sehr über den Artikel und die daraus entstandene Diskussionsgrundlage.
Danke für die Ergänzung. So macht Bloggen wirklich Spaß, aber das nur am Rande :-)
„dass Google die Integrität der Bestandsdaten höher priorisiert als die Neuaufnahme in den Index, da das Primärziel einer Suchmaschine ist gültige und gute Ergebnisse zu liefern und im Zweifel nicht ganz so aktuell zu sein, als dass man den Nutzer damit verprellt ihn mehrfach auf Seiten oder Ressourcen zu schicken, die so nicht mehr existieren.“ – Perfekt formuliert, danke. So meinte ich das auch. Der Prozentsatz spielt letztlich keine Rolle :-)
Bei dem Absatz davor bin ich mir nicht sicher, ob ich es richtig verstanden habe. Vielleicht das als Ergänzung / Anregung: Der Googlebot 2.1 (der normale Bot) crawlt HTML-Seiten. Wenn er etwas findet, was nur im entferntesten anch Bild-URL aussieht, dann setzt er es auf die ToDo-Liste des Bilderbots (Googlebot Image 1.0). Der überprüft ausschließlich (!) Bild-Dateien. Wenn eine Datei existiert, dann setzt er dieses Datei inkl. Fundort-URL auf eine ToDo-Liste für den Bilderkennungs-Algo. Danach gelangt das Bild dann als Meta-Bild in den Google-Index.
:-)
Ich glaube wir haben mit dem Kommentar unseren Konsens gefunden und sprechen vom Selben :)
Danke dafür.
Interessanter Artikel. Falls es jemanden interessiert – es gibt verschiedene Kompressionsmethoden für Bilder. Am besten hat sich bei mir Lanczos3 bewährt, weil dieser die Fotos nicht nur kleiner – sondern auch schärfer macht (Teil von ImageMagic oder anderen Tools). Bin überhaupt erst auf das Thema gestoßen, weil ich meine Bilder noch zu optimieren habe. Niemand mag unscharfe oder schlechte Modifikationen.
Vielen, vielen Dank für den ausführlichen Artikel und die Grafiken, die das sehr gut veranschaulichen.
Eine Frage stellt sich mir jedoch:
Gibt es einen Rankingbonus dafür, wer das Bild zuerst hochgeladen hat, wenn es mehrere Kopien des Bildes gibt? Ist es dann ein Nachteil, wenn ich das Bild verändere (Komprimierung/Größe), weil dann jemand anderes das Bild zuerst hatte? Sprich, gibt es bei den Referenz-URLs ein zeitliches Ranking, dass als Rankingfaktor mit einfliesst?
PS: Es gibt auch seriöse Webseiten, die ein „24“ in der URL haben ;)
Danke, freut mich. Nein, das Datum, an dem Google ein Bild zuerst findet, spielt offenbar keine Rolle – zumindest nicht bei der Frage, welche Seite den Link aus der Bildersuche bekommt. Eine Zeitlang war sogar des Gegenteil der Fall: da wurde die Seite verlinkt, wo Google das Bild zuletzt gefunden hatte (wegen Freshness).
In der Tat kann es einen Bonus geben, wenn man ein Bild, dass Google bereits indexiert hat, in der Dateigröße verkleinert. Eine Beispiel, wo das eine Zeitlang sehr gut geklappt hat, ist Pinterest, siehe: https://www.tagseoblog.de/das-problem-pinterest
Aber das scheint sich inzwischen auch schon wieder zu normalisieren.
PS: aber nur sehr wenige ;-)
Moin Martin! Top Artikel, musste mich gerade etwas mehr in die Thematik hineinfuchsen.
Ich glaube nicht, dass viele Leute den Dateinamen auch berücksichtigen. Somit ein schöner Vorteil für alle, die das verstanden haben.
Viele Grüße
Christoph
Hi Martin, eine Frage tut sich mir auf bei der Komprimierung von Bildern: Ist es zu hoffen , dass Google das veränderte Bild „wiedererkennt“ oder ist es ist durchaus wahrscheinlich?
Viele Grüße
Philipp
Sehr guter Beitrag!
Ich habe mir die Frage auch schon gestellt, was eigentlich mit dem guten Ranking eines Bildes geschieht, wenn dieses irgendwie verändert wird.
Vielen Dank für die ausführliche Erklärung.
LG
Hallo Martin, super, dass ich deinen Artikel gefunden habe. Es war etwas enthalten, dass bei uns im nächsten Team Meeting besprochen wird. Was für mich noch nicht ganz klar war. Sollte ich mich bei der Gestaltung eigener Bilder an Bilder von Google halten die bereits in der Bildersuche aufscheinen um so die Wahrscheinlichkeit für Text / Bild Relevanz zu erhöhen? Gruß, Michael
Hi Michael,
ja, das ist durchaus empfehlenswert (natürlich nur solche, die man nutzen darf). Ich würde aber immer empfehlen, auch noch zusätzlich eigene Bilder zu den relevanten Artikel-Keywords zu erstellen und einzubinden. Dann wird es noch viel „wirkungsvoller“ :-)
Kannst ja noch mal hier nachlesen: https://www.tagseoblog.de/bilder-nutzen-fuer-organisches-seo-inkl-workflow-tipp-seo-campixx-vortrag
Hi Martin! Hope you can answer to my question.
Is there any proof that either Google is able to index an image on Google Image Search based only on the content of the image, or that the content of the image itself plays any role in being indexed?
Two scenarios:
1. Let’s say that I have an image of a black cat and I put it in a specific page with no other information, no tags, no text, no filename, just the image. Will it be indexed by Google under „black cat“ query?
2. Let’s say that I have an image of a black cat and I put it in a specific page with tons of information not about a black cat but about a white dog, so alt text will be about white dog, and so on in title, text and description, etc. Does the fact that the image is actually a black cat and not a white dogs count in any way to Google, assuming that it will be ranked under query „white dog“ query?
Thank you
Kommentare sind geschlossen.